UE/UMG:ステップ移動マテリアル▼
こんにちは。最近卒業制作でモリモリUE5をしばいてゲームを作っている修羅場のAlgo_Ayugonです🐜
今回は卒業制作の中で作った簡単なマテリアル(シェーダー)を紹介します(UnrealEngineで作ってますが、Unityとかでも同様だと思います)。
こういうやつです。

そう、「会話UIの文章の最後で上下運動しがちな”▼”」ですね。使いたい場面は多いと思います。
Material Domain:User Interface、Blend Mode:Maskedに設定して以下のように組みます。

少し解説。

サインカーブ(-1~1を反復する)を【If】ノードに繋ぎ、0より大きい時は0.1を、0以下の時は0を出力します。
グラフにするとこうですね。矩形波的な形になります。

「0.1」というのがミソです。1以上にはならない方がまともな動きをします。

【TexCoordinate】ノードから2Vector(U,V)をBreakして、Vに先ほどの出力を加算します。ここで、UV座標系は0~1で1ループとなっているので0.1にしたわけです。
おしまい! 簡単ではありますが、シェーダー作成・数学初心者にとってはちょうどいい勉強になりました。
おまけ
数学とUVがわからなすぎてめちゃくちゃ組んだらできたグリッチマテリアルのレシピも置いときます。ご自由にお使いください(?)

ただマテリアルアニメーションで矩形波みたいに上下させたかっただけなのに数学がわからなすぎて変な動きになってしまったが、なんかかわいいからこれでいいや感がある#UE5 pic.twitter.com/et6qkULpEk
— Algo_Ayugon@いぬ (@ayugon_vrc) 2023年2月3日
かわいいな…。 これはまだマシな動きしてますが、数値を変えることでバグった初代ポケモンのポケモンアイコンみたいな動きにもなります。GIFに動きが映りきらなかったので、各自試してみてください。
Algo_Ayugon
BlenderとxNormalを用いた非破壊ノーマルベイク(UV一致)
Algo_Ayugonです。
共有する機会があったので、自分のノーマルベイクのワークフロー(Blender)について書いてみたいと思います。
こんな人向け!
- ノーマルマップを超綺麗にベイクしたい
- ケージとかブロッカー作んのめんどくさい。あと干渉部分切り離すのもめんどくさい(これに関しては結局他のベイクのために切り離す必要が出てくる…かも…)
- スカルプトとかやりとうない。ポリゴンモデリングが好きなのでポリゴンを生かしてベイクしたい
- 三度の飯より非破壊ワークフローが好き。非破壊ワークフローと結婚したい
- トポロジー整理には自信がある
こんな人はたぶん向いてない
スカルプト→リトポロジー→ノーマルベイク という感じのワークフローを既に確立している
- スカルプトワークフローでもハイポリとローポリでUV一致させる方法があれば適用できるので、あったら教えてください! ポリゴンモデリングが好きなのであんまりやんないと思うけど仕事とかで使うかも
この方法の威力
まずはこれを見てください


お分かりいただけただろうか
概要
- ローポリモデル作る(色々下処理有り)
- ローポリモデルにサブディビをつけてハイポリ化する(UV境界が変わらないオプションをつけること)
- xNormalでUV一致オプションを用いてベイクする
- Substance Painterにベイクテクスチャをインポートして煮るなり焼くなりする
やっていきましょう
1. ローポリモデル作成
普通にモデリングします。
「サブディビジョンサーフェスモディファイアー」をつけた時にも綺麗になるようにトポロジーに気をつけることが最重要です。なので、モデリング中もモディファイアーの表示/非表示を切り替えて確認しながらやっていきます。
- 「クリース辺」を使うとサポートエッジを使わなくてもエッジを尖らせることができます
- 所謂サポートエッジを使うとその分余計なポリゴン数が増えるのでゲームモデルとしては良くないです。一応、Setup Static Objectの機能を使うと指定した辺を削除して複製やエクスポートができたりしますが、手間は手間なのでやっぱり使いたくないです
- サブディビは曲面に三角面があると汚くなりがちなので、できるだけ四角面で作ります。ですが、ポリゴン数やワークフローの快適さとの兼ね合いもあるのである程度は許容します(クリース辺やシャープ辺で誤魔化せたり誤魔化せなかったり)。トポロジー弄りぢからが試される!
- 当たり前ですがUVは開きます。非破壊ワークフローなので後から修正効きますし、とりあえずベイクできる形に開くだけ開きます
- Nゴンは潰せ 特にサブディビつけてるのでNゴンあると本当に大変なことになります
2. ハイポリモデル作成
とは言ってもサブディビジョンサーフェスモディファイアーつけたままモデリングしてるので作成もクソも無く、もう既に作成されているはずです。ここが強いね!
なので設定周りについて捕捉します。
- 細分化の値は2~3くらいがいいでしょう。それ以上にしてもあんまり変わりません
- !重要! オプションを「シャープ」に変更します。これにより、ローポリとハイポリでUVが変わらなくなります。
- Blender3以上だと詳細設定を開いて、「UVスムーズ:コーナー、接点、凹面を維持」「境界スムーズ:コーナーを維持」が良いと思います。まだ試してませんが、精度が上がってるのかな?
- xNormalが四角面やNゴンがあるメッシュを拒否することがあるので、一応「三角化モディファイアー」もつけておきます。エクスポート時に三角化してもいいです。
ローポリとハイポリができたらエクスポートします。fbxでもobjでもいいですが、xNormal向けのやつはなんとなくobjで出してます。結局Substance PainterではIDマップ用に頂点カラー使いたいんでfbxで出すんですが…。
ローポリをエクスポートするときはサブディビを外し、ハイポリをエクスポートするときはサブディビをつけてやるだけです。簡単!(Substance Painterでのベイクを考慮すると、複製等をしてメッシュ名はハイポリは_high、ローポリは_lowと命名しておいた方が便利かも)
3. xNormalでベイク
参考:
xNormalをインストールしておきます。なんだこの奇天烈なGUIは…。でも優秀なんです。使ってるうちに愛着沸いてくるので大丈夫です。
ローポリとハイポリをセットします。この時、ローポリ側の設定で「Match UVs」にチェックを入れます。これでUV一致ベイクができます!!!!!!!
あとは普通に(?)xNormalでベイクするだけです。一応、いつもの設定
- Mesh Scaleは16(なんでもいいと思いますがたぶんローポリとハイポリで同じ値じゃないと駄目です。デフォルトでもいいのかもしれない…)
- Edge Padding:1Kなら4、2kなら8
- Antialiasing:ノーマルマップなら4、AO等なら1
- ノーマルベイクは爆速なので高くても大丈夫ですが、それ以外は時間かかるので
xNormalではノーマルマップ以外にも様々なマップを焼くことができます。Substance Painterで使うやつだとAmbient OcclusionやCurvatureをここで焼いてもいいですが、正直ノーマルマップ以外はSubstance Painterの方が綺麗な気もするので後回しでもいいですし、一応焼いておいて綺麗な方使うでもいいです。
4. Substance Painterにインポート
今は買い切りの2020版しか持ってないのでそれで書きますが、たぶんAdobe版でも変わらないと思います。たぶん。
「ファイル→Import resources」でxNormalで焼いたマップを指定してImportし、TEXTURE SET SETTINGSのMESH MAPS(Bake Mesh Mapsボタンがあるところ)のスロットにドラッグ&ドロップしてターンエンドです。
Substance Painterでベイクする時は、ノーマルマップは焼かないようにしましょう。また、他のマップを焼くときもハイポリモデルがあると綺麗になるので、High Definition Meshesのところに指定しておきます。By Mesh Nameで焼くといいよとか、IDマップ焼くときはハイポリは外した方がいいよとか色々ありますが今回の主役はSubstance Painterではないので割愛します。
そんな感じで非破壊を維持したまま超綺麗なノーマルを焼くことができます。さいこ~~~~~~~~~~!
それでは皆さんよきベイクライフを。
Algo_Ayugon
Rのgt表をpandoc-crossrefで相互参照してPDFにした(修論)
この記事は修論でRのgtパッケージで出力した表をMarkdownに貼り付け、pandoc-crossrefを使って相互参照された状態のPDFを出力したときの備忘録です。ピンポイントすぎる気はしますが、同じようなことでハマっている人の役に立ったら幸いです。
はじめに
筆者のレベル
やりたいこと
Markdownで修論を書いて、pandocでPDFにして提出したい!
基本的にはこれらの記事を見てやれてます。ありがたや…
問題
卒業論文に限らず、論文の類を書くときは図表の「相互参照」をしなければなりません。(W●rdにも相互参照機能はありますが、卒論の時にそれをぐちゃぐちゃにされてしまったトラウマがあるので二度とW●rdで執筆したくありませんが、それはまた別のお話)。
Markdown+pandocで相互参照をするときは、pandoc-crossrefを使いますが、ここで問題発生。「図」は図なので画像でいいのですが、どうやら表はMarkdown形式かLaTeX形式でテキストとして書かないと(図とは区別された)「表」として認識してくれないらしい(画像のままいける方法あれば誰か教えてください)。Rのgtパッケージで画像ファイルとして出力したものを貼り付ける想定でいた私はまずそこでちょっと困りました。
ただ、調べてみるとgtパッケージで作った表はLaTeX形式(.tex拡張子)でもエクスポートできるらしいのでほっと一息。
ここからは実際にコード書いて説明していきます。せっかくなので、前記事で作った表をベースにやっていきましょう。
基本的に前記事と同じコードですが、最後に表に「タイトル」をつけていることに注意してください。(gtの使い方については調べてください)
library(janitor) #janitorパッケージ読み込み library(tidyverse) #tidyverseパッケージ読み込み library(gt) #gtパッケージ読み込み df <- warpbreaks #サンプルデータ読み込み cross <- tabyl(df, wool, tension) #クロス集計表を作る cross_rate <- adorn_percentages(cross, "row") #行(横)割合に換算 cross_rate_P <- adorn_pct_formatting(cross_rate, digits = 2) #%に換算 tidy_df <- gather(cross_rate_P, key=tension, value=percent, -wool) #整然データに #gt表を作る Table <- gt( tidy_df, rowname_col = "tension", groupname_col = "wool" ) %>% tab_header(title="テスト") #タイトル Table #.texで保存 gtsave(Table,"Table.tex")
こうしてできたTable.texをメモ帳等、文字化けせずプレーンテキストで読めるテキストエディタで開いて、Markdown文書にコピペします。
--- tableTitle: "表 " tblPrefix: "表." header-includes: - \usepackage{longtable} - \usepackage{booktabs} --- # 表の相互参照がしたい! \captionsetup[table]{labelformat=empty,skip=1pt} \begin{longtable}{ll} \caption*{ {\large テスト} } \\ \toprule & percent \\ \midrule \multicolumn{1}{l}{A} \\ \midrule L & 33.33\% \\ M & 33.33\% \\ H & 33.33\% \\ \midrule \multicolumn{1}{l}{B} \\ \midrule L & 33.33\% \\ M & 33.33\% \\ H & 33.33\% \\ \bottomrule \end{longtable} [@tbl:test]を見てください!
ここで違和感。なんか参考にした記事のLaTeX表と見た目違うくない?(特に上の方)
とりあえず出力してみます。
pandoc test.md -o test.pdf -F pandoc-crossref --pdf-engine=lualatex -V CJKmainfont=msgothic.ttc
※文字化けとか対策にlualatex使ったりフォント指定をしたりしています。
結果

お!なんかちゃんと表は出力できたっぽい!しかしうまくいってないところもある。
- \label{tbl:levels}を挿入する場所がわからない
- 本来なら「表1. 」が「テスト」というタイトルの前に挿入されるはずなのだけど、そうなってない
これらを解決するため、LaTeXなんもわからんなりに色々弄って調べました。
解決
結論
\captionsetup[table]{labelformat=empty,skip=1pt}という行が(おそらくgtのおせっかいで)入っているせいで「表1. 」が挿入されなくなっているので、消去する。
\label{tbl:levels}はタイトルテキストの直前に挿入するとうまくいく。
captionのところががちゃがちゃした書き方になっていてそれもなんかうまくいかない要因になってるっぽいので、シンプルにする。
参考:LaTeX表組

こんな感じでヘッダーをこちょこちょします。
結果

やったー! 相互参照ができた!!! めでたし。
これで修論を書くことができますね! あと1ヵ月しかねえぞ!
がんばります。それでは。
Algo_Ayugon
キャラモデリング向け外部ツールまとめ(Blender,Unity)
2022/01/02:FANBOXからブログに移植。ついでに分類したり厳選しなおし。
これがあると(主にキャラ)モデリングが爆速になるというか、もはやこれ無しでは考えられないみたいなツールのまとめ。VRChat向けのもの含。
下線がついてるやつはその中でも特に重要。
【Blender】
2.8系で動作確認。2.9系でも基本的には動くと思う。
モデリング系
●Mesh Check BGL Edition (https://gumroad.com/l/mesh_check_BGL_edition)
Nゴン等をリアルタイムに検出・ハイライト表示
●F2(標準)
Fキー連打で面張り
●Loop Tools (標準)
なんか色々と頂点を整えてくれる
●Mira Tools(https://github.com/mifth/mifthtools)
カーブで頂点を整列。髪の毛で使えることがある
●Edge Flow (https://github.com/BenjaminSauder/EdgeFlow)
Mayaみたいにエッジループを曲線的に良い感じに整列
スキニング系
●Lazy Weight Tool(https://bookyakuno.com/lazy-weight-tool/)
(有料)ウェイト設定の効率化
UV系
●TexTools(https://github.com/SavMartin/TexTools-Blender)
UVの整列、回転、グリッド化(類似アドオン色々あるので好きなやつを使おう!)
●Texel Density Checker (https://gumroad.com/l/CEIOR)
UV島のテクセル密度を計算、別の島にコピペ
●UVPackmaster PRO (https://uvpackmaster.com/)
(有料)UV島のパッキング。オブジェクト毎に固めてくれたり短径(長方形)で指定した場所に詰めてくれたりするのが便利
テクスチャ系
●Auto Reload Images(https://github.com/samytichadou/Auto_Reload-Blender_addon)
テクスチャの更新をワンクリック・またはほぼ自動で反映
シェイプキー系
●CATS Blender Plugin(https://github.com/michaeldegroot/cats-blender-plugin)
主にリップシンク用シェイプキーの半自動生成、その他VRChat向け調整
●Apply Modifier(https://github.com/Taremin/ApplyModifier)
シェイプキーを保持したままモディファイヤーを適用。ミラー、アーマチュア、法線転写に。
【Unity】
●Copy Components By Regex(https://github.com/Taremin/CopyComponentsByRegex)
コンポーネントの一括移植
●VRCHierarchyHighlighter (https://booth.pm/ja/items/1326573)
Hierarchyを見やすく(類似アセット色々あるので好きなやつを使おう!)
●SkirtSupporter(https://sites.google.com/view/skirtsup)
ダイナミックボーンの貫通対策
●VRCAvatarEditor beta(https://booth.pm/ja/items/1258744)
BoundingBoxやAnchorTargetの設定
以上。ツール開発者様方には頭が上がりません。
Algo_Ayugon
Rのdataframe使ってクロス集計した(修論)
この記事は修論でRでクロス集計したときの備忘録です。クロス集計をやりたい場面は結構あると思うので、卒論書く人とかの役に立てば幸いです。
はじめに
筆者のレベル
- 数学超苦手(だけど3DCGのために行列をちょっと自学しはじめた)。プログラミングの素養はそんな無いけどコンソールとかに抵抗はない(むしろRコマンダーとかGUI使う方がなんかめんどい)。
- 卒論でもRはちょっと触った。ディレクトリの概念とか簡単な関数くらいはわかる。
- 修論のためにRをもっと色々としばいて学び始める。前記事→「Rでデータを綺麗にした(修論編)」
という感じで、相変わらず初心者です。
やりたいこと
- クロス集計をしていい感じの図表を出力したい。
やっぱりExcelは嫌いなのでRでやりたい。
問題
- クロス集計をしてくれる代表的な関数としてprop.table()があるが、dataframeをtableに変換しないと使えない。tidyverseパッケージを中心に運用したいので、dataframeはずっとdataframeのまま運用したい。(変換を二回も挟むときったねえコードになって発狂する)
- いわゆるクロス集計表と呼ばれるものは、そのままだとggplot2やgtはうまく読み込んでくれない。「整然データ」と呼ばれるようなdataframeに変換する必要がある。
【参考】「整然データとは何か」
ggplot2パッケージとgtパッケージはdataframeを使ってなんかいい感じのグラフと表が作れるなんかいい感じのパッケージで、ここには詳しく書きませんがネットにも情報が多いので調べてみてください。
解決
1. janitorパッケージを使う
janitorパッケージというものがあるらしく、prop.table()の代わりにこれのtabyl()関数と adorn_percentages()関数を使えば入力も出力もdataframeで扱えて最高でした。
【参考】「janitorパッケージでtidyな度数分布表やクロス表を作成」
2. gather()関数を使ってクロス集計表を整然データに変換する
クロス集計表に限らず、色々な分析結果をggplot2やgtに読み込ませるためにコードを書いて無理やり分類のための列を付与したり並べ替えたりガチャガチャやったりしてたのですが、gather()関数が使える場面では一発だったりするようです。特にクロス集計表の場合は有効です。
【参考】「tidyr::gather( )とtidyr::spread( )でデータフレームを自在に変形する」
実践
dataframe読み込み
クロス集計ができそうな(カテゴリカルデータが2種類以上ある)Rのサンプルデータとしてwarpbreaksを使います。
#サンプルデータ読み込み df <- warpbreaks
warpbreaksの中身はこんな感じです。
> head(df) breaks wool tension 1 26 A L 2 30 A L 3 54 A L 4 25 A L 5 70 A L 6 52 A L > str(df) 'data.frame': 54 obs. of 3 variables: $ breaks : num 26 30 54 25 70 52 51 26 67 18 ... $ wool : Factor w/ 2 levels "A","B": 1 1 1 1 1 1 1 1 1 1 ... $ tension: Factor w/ 3 levels "L","M","H": 1 1 1 1 1 1 1 1 1 2 ...
woolとtensionがFactor型の属性列なのでとりあえずクロス集計ができそうですね。それぞれ水準はwoolはAとB、tensionはLとMとHがあるみたいです。
クロス集計するぞ!
さっそくjanitorパッケージを使ってみます。woolとtensionのクロス集計をしてみましょう!tabyl()という関数を使います。
(説明のため、一旦演算子%>%は使わずに書いていきます。途中経過を保存できるメリットもあるしね!)
library(janitor) #janitorパッケージ読み込み cross <- tabyl(df, wool, tension) #クロス集計表を作る
【実行結果】
> cross
wool L M H
A 9 9 9
B 9 9 9
できたあああ!!!しかもちゃんとdataframe型です!
(綺麗すぎてびびりますが、たぶんこれ実験結果の属性じゃなくて実験計画の段階でこうなるように操作されているっぽいです。そういう場面で確認のためにクロス集計を使う場面もあるだろうしまあいいでしょう。できたことが大事!)
割合も出してみましょう。adorn_percentages()関数を使います。
cross_rate <- adorn_percentages(cross, "row") #行(横)割合に換算
(今回は行(横)割合を出していますが、"row"を"col"に変えると列(縦)割合になります。
【実行結果】
> cross_rate
wool L M H
A 0.3333333 0.3333333 0.3333333
B 0.3333333 0.3333333 0.3333333
出せました。これは合計が1になる割合表示なので、%表示にしたいと思います。
……ここで、愚かな私はそれをmutate_at()と100倍するだけの自作関数を組み合わせて無理やり(?)実装してしまったのですが、ちゃんとドキュメントを見たら…そのための関数も…ありました……adorn_pct_formatting()関数を使います! 英語でもめんどくさがらずにドキュメントは読もう!
cross_rate_P <- adorn_pct_formatting(cross_rate, digits = 2) #%に換算
digits=のとこの数字を変えると小数点以下どこまでで丸めるかを指定できます。
【実行結果】
> cross_rate_P
wool L M H
A 33.33% 33.33% 33.33%
B 33.33% 33.33% 33.33%
ご丁寧に単位までつけてくれました。あれこれ文字混入してる(実際型もchrになってる)けど大丈夫なんか?と思ったけどこのままでもggplot2につっこんでも大丈夫そうだったので、なんか大丈夫な内部構造になってるんでしょう!Rなんもわからん!
それが気持ち悪い人は以下の私が作った愚かなコードを使ってください。
library(tidyverse) #tidyverseパッケージ読み込み
#100倍するだけの関数を作成
caP <- function(x){
P <- x*100
return(P)}
cross_rate_P <- mutate_at(cross_rate, vars(-wool), caP) #%に換算
xを100倍するだけの関数…かわいいね…。(mutate_atのfunctionのところに直で*100とか入れても動かなかったのです。これもなんかいい方法がありそう…Rなんもわからん…)
整然データに直して図表にするぞ!
クロス集計表が欲しいだけの人はここまでで終わっても大丈夫です。ここからは、それを元に表とかグラフとかを作っていきます。
tidyverseパッケージ内のgather()関数をつかってクロス集計表を整然データのdataframeに変換します。
library(tidyverse) #tidyverseパッケージ読み込み tidy_df <- gather(cross_rate_P, key=tension, value=percent, -wool) #整然データに
【実行結果】
> tidy_df wool tension percent 1 A L 33.33% 2 B L 33.33% 3 A M 33.33% 4 B M 33.33% 5 A H 33.33% 6 B H 33.33%
記事を見ても直感的に使い方を理解するのに時間が掛かってしまい、説明し直すのもちょっと難しいのですが、たぶん以下のような感じです。

記事の説明に乗っかると、wool列以外のL,M,H列を”ラベル”にしてtensionという名前を付け直し、wool列以外に格納されている値をvalue列(percentと命名)に並べる、という感じでしょうか。
とにかく、これで整然データになりましたので、gtとかggplotに読み込ませていきます。
library(gt) #gtパッケージ読み込み Table <- gt( tidy_df, rowname_col = "tension", groupname_col = "wool" ) Table

やったぜ。
#ggplot2でグラフ作成 Col <- ggplot(tidy_df, aes(x=wool, y=percent, fill=tension)) + geom_col(width = 0.5) Col
(ggplot2パッケージはtidyverseパッケージの中に入ってるので読み込みなおす必要は今回は無いです)

やったぜ。
gtやggplotに読み込ませられたので、あとは煮るなり焼くなりしてなんかいい感じの図表を作りましょう。その方法についてはここでは触れないので、インターネットに探しに行ってください。
これで何でもかんでもクロス集計することができますね。ではよきデ―タ弄りライフを……私も修論まだ一文字も書いてないので、こんなブログ書いてないで本腰入れましょうね。それでは。
Algo_Ayugon
インセインシナリオのレシピ(初心者PL向け協力型編)
この記事はTRPGシナリオ、それもインセインのシナリオを作るための備忘録です。
TRPGの中でもインセインは、慣れてしまえばかなり楽で破綻も少なくGMができる非常に良いシステムですが、シナリオ制作をしようとすると結構癖があるとも思っています。しかし、これも慣れてしまえば結構楽です。(もう私はインセインシナリオしか作れない回せない身体になってしまった…)
今回は、初心者PL用にとてもシンプルに作った『肉霊製造工場』という協力型のシナリオを例に説明します。
- 準備するもの
- 『肉霊製造工場』の概要
- (当時の)必要要件
- (ここから先、激しくネタバレ)
- 1. コンセプト・テーマを固める
- 2. やりたいこと(シーン)を決める
- 3. PCHO(使命)を決める
- 4. シーン数を確認し、HOを書く
- 5. 狂気カード枚数と種類を決める
- 6. エネミーデータを決める
- 7. (必要に応じて)マスターシーンを考える
- 何かができたぜ。回してみるか。
準備するもの
インセインルールブック、サプリ
シナリオを作るなら、やっぱり必要です。
何らかのテキストエディタ
私はNanaTerryを使っていますが、別に何でもいいです。HOの管理に便利で、階層構造を作れて、そのアウトラインが見やすいものをおすすめします。最終的に印刷したり、公開したりすることを考えると、MarkdownとかGoogleドキュメントに直書きとかでもいいかも。
『肉霊製造工場』の概要
シナリオ本文はここから読めます(だいぶ昔に公開したシナリオで、pixiv小説媒体しかなくて読みにくくてすみません)。
(当時の)必要要件
このシナリオは、大学のTRPGサークルの新歓用のシナリオとして作りました。そのため、まず、かなりきつい縛り、必要要件がありました。
- PLのうち、2人は全くTRPGをしたことがない新入生を想定、もう2人はサポートしてくれる経験者PLが入ってくれる(はず)。
- 「短時間枠」を担当。セッションは本編2~3時間(この時は対面セッション)で終わり、終電に間に合わせなければならない。
逆に言うとこれ以外は割とやりたい放題です。
(ここから先、激しくネタバレ)
続きを読むRでデータを綺麗にした(修論編)
この記事は修論で実施したアンケートの回答データを分析するため、Rでいい感じに整形したときの備忘録です。
見せたい気持ちは山々ですが、アンケートのデータをそのまま載せるとヤバいし、かといってサンプルデータをこしらえる気力も無いので抽象的な書き方が多いです。それでも卒論とかでRをやろうとしてる人とかの役に立ったら幸いです(高度なことはやらないですたぶん)。
はじめに
筆者のレベル
数学超苦手(だけど3DCGのために行列をちょっと自学しはじめた)。プログラミングの素養はそんな無いけどコンソールとかに抵抗はない(むしろRコマンダーとかGUI使う方がなんかめんどい)。
卒論でもRはちょっと触った。ディレクトリの概念とか簡単な関数くらいはわかる。
という感じで分かる通り、かなり初心者です。
やりたいこと
色々事情があって「日本語 or 英語」×「紙回収を手打ち or Googleフォーム回収」=4種類(厳密には6種類…ひえ…)の回答データセットが混在しており、それらを分析前に1つのデータベースにまとめる。それぞれ微妙に言語やフォーマット等が違うのでそれも統一する。
なぜRを使うに至ったか
上記のことはゴリ押しでやればExcelでもできます。ですが
筆者はExcel(というかOffi●e系ソフト)が嫌い。元データはできるだけ触りたくなかった。
中間報告(ゼミ等)が必要だったりするのもあり、アンケートが少しずつ集まるその都度に分析を進める形になる見込みだった。毎回手作業でしていてはめんどくさいし、何よりミスが怖いので、ある程度自動化したかった。
結局分析自体もRでやるので、練習・肩慣らしも兼ねて。
やっていく
ディレクトリを指定
いつも使ってるディレクトリが結構奥深くにあって、「ファイル→ディレクトリの変更」でいちいち指定するのがかなりめんどくさいので、関数で指定してやります。
setwd("ディレクトリ名")
で指定できます。
一度ディレクトリを開いてから、
getwd()
を実行するとディレクトリ名を吐き出してくれるので、コピペすると良いです。次から楽しましょう。
パッケージ呼び出し
今回はdplyrパッケージとstringrパッケージを使うので、
library(dplyr) library(stringr)
で呼び出しておきます。色々とデータ整形に便利なパッケージらしいです。
データを読み込む
data <- read.csv("ファイル名")
で読み込みます。
読み込むと、Rくんはこれを単なるmatrix(行列)ではなくいきなりdatabaseとして扱ってくれます。何も指定しないと、1行目が列名として使用されます。
1列目を除去する
紙回収で私が手入力したcsvファイルには、ミス等のチェック用に1列目に各解答用紙と紐づけたid番号を入力してあります。Googleフォーム(スプレッドシート)からDLできるファイルの1列目には「Timestamp(フォームが提出された日時時刻)」が格納されています。
今回は、どちらも使用しない(分析用のidは必要に応じて、マージしてから改めて付与する)ので1列目をまとめて除去します。
data <- data[,-1]
[ , ]の左側は行列の行の方で、右側は列の方を指します。-(マイナス)をつけると「その行(列)を除去する」という操作になります。空欄なら何も起こりません。
列名を付け直す
4つのデータセットは現在それぞれ列名が結構バラバラなので、命名しなおして統一します。
colnames(data) <- ("A", "B", "C"...)
みたいな感じで全て同じものを入力しましょう(上書きされます)。
※ちなみに、Rは日本語に対応しているはずなのでこれは私の趣味ですが、基本的にRコンソール上の文字列には日本語(2バイト文字)は使いません。2バイト文字を使うと、入力や選択の時になんか2バイトの分ズレて凄く使いにくくなるからです2。行の後ろの方であればあまり影響がないので、コメントアウトとかには容赦なく日本語使います。英語ワカラン。
列(属性)を足す
4つのデータセットにはそれぞれ「日本語 or 英語」×「紙回収を手打ち or Googleフォーム回収」という属性があるので、マージ前にその情報を付与します(後で言語・形式という実験方法の差による影響がないかを検証するためです)。
dplyrパッケージの中に、mutate()関数というピッタリなものがあります。databaseの列の末尾に新たな列を追加し、任意の値で埋めてくれます。
「日本語」版のアンケートを「紙回収して手打ち」したデータセットの場合、
data <- mutate(data, Language = "Japanese") data <- mutate(data, Format = "Paper")
を実行すると、LanguageとFormatという列名の列が末尾に追加され、Languageの列にJapaneseが、Formatの列にPaperがすべて入力されます。
(Googleフォーム産)順位を数値化
この辺からちょっと苦しくなってきます。
今回とったアンケートでは、8列目までが順位データとなっているのですが、Googleフォームでやる3とこんな感じになってしまいます。
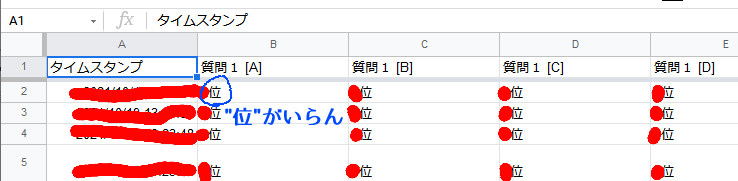
最終的に整数データとして扱いたいため、"位"とか、英語版なら"th"とかがとても邪魔です。
ここでもmutate()が役に立ちます。先ほどの用法では新たな列を作成するために用いましたが、引数に元ある列を指定することで処理後の値で中身を上書きできます。mutate()の最後の=の後には別の関数を実行することができます。
”位”の除去(というよりは、数値の抽出)にはsubstr()かstr_sub()を使います。たぶんどっちでもあんまりかわらないです(str_sub()を使うにはstringrパッケージが必要です)。
data <- mutate(data, A = str_sub(A,1,1))
という感じで、A列のそれぞれの中身の文字列の、1文字目~1文字目(つまり1文字目のみ)を抽出できます4。
これを8回やるわけですが、めんどい! 何か良い手はないのか!とインターネットを探してみると、mutate_at()やらacross()やら、mutate()を複数列に渡って実行する用の関数バリエーションがあるらしい。これや!と思ったのですが問題発生。
なんかmutate_at()の中身の関数は、引数を色々使うやつだとRぢからが無いと使えないらしい?! 僕R初心者です。
参考: https://knknkn.hatenablog.com/entry/2020/06/23/113455
とにかく普通に使おうとして動かなかったので、いうても8回しかやらないこともあってごり押しでやることにしました。
data <- mutate(data, A = str_sub(A,1,1))%>% #"位"を除去 mutate(B = str_sub(B,1,1))%>% mutate(C = str_sub(C,1,1))%>% mutate(D = str_sub(D,1,1))%>% mutate(E = str_sub(E,1,1))%>% mutate(F = str_sub(F,1,1))%>% mutate(G = str_sub(G,1,1))%>% mutate(H = str_sub(H,1,1))
はい全部書いた。
%>%はdplyrパッケージを入れると付いてくる、パイプ演算子と呼ばれる、処理を連鎖してくれるやつ。data <- mutate(data,あたりまでの記述を省略できるので、こんだけ泥臭く書いても若干ですがスッキリしますね。
こいつらは元は文字列だったので、整数型(integer)として定義しなおしてあげます。それに使う関数as.integer()は、なんと!引数が要らない関数なので!今度こそmutate_at()が使えます。やった~~~!!
data <- mutate_at(data, vars(A:H), list(as.integer)) #型変換
この一行で8列全部型変換してくれます。超楽ですね。(list()は最初はfuns()にしてたけどR君に今は非推奨ダヨ!となんか怒られたのでよくわからんまま変えました)
属性データを英語に統一
9列目からは性別だとか年齢だとかの回答者属性の列となっています。しかし自分で手打ちしたやつは作業簡便化の為に数字(コード)だし、Googleフォーム産のやつは前述の仕様のせいで日本語だったり英語だったりで、全部バラッバラでこのままだと集計すらできないので、統一します。
やること自体はさっきと似てます。mutate()の中でstr_replace()を実行して置換しまくります。
data <- mutate(data, Gender = str_replace(Gender,"男性","male"))%>% #Gender表記統一 mutate(Gender = str_replace(Gender,"女性","female"))
上記は"男性"を"male"に、"女性"を"female"に置換する例です。これを属性と水準の分だけ、全部やります。やりました。コピペ作業ではあるけど、大変。
CSV形式でエクスポート
整形した後は、
write.csv(data,"ファイル名")
でcsvとして吐き出せます(オリジナルとは別名にしときましょう。フォルダを分けたりしてもいい)。Excelで開いて確認してみるとちゃんとなってると思います。
上記までをRスクリプトとして保存、実行
ここまでをまとめると、「日本語」版のアンケートを「オンライン回収」したデータセットの例だと
#オンライン日本語版アンケート
data <- read.csv("Online_Ja.csv")
data <- data[,-1] #1列目削除
colnames(data) <- ("A", "B", "C"...)
data <- mutate(data, Language = "Japanese")
data <- mutate(data, Format = "Online")
#順位を数値化するやつ(省略)
#属性データを英語に置換するやつ(省略)
Online_Ja <- data #後の為に格納
write.csv(data,"Formated_Online_Ja.csv") #とりあえず書きだしもしとく
みたいな感じですね。
これを「ファイル→新しいスクリプト」からRエディタを開いて、そこに打ち込んでそれぞれのデータセット別に名前(上の例だと"Online_Ja.R")をつけて保存しておきます。
保存したRスクリプトは、source()関数を使って
source("スクリプト名.R")
とかで実行できます。RStudio使ってるとRunとかもできて便利ですね。
データセットをまとめる
形式が揃うように整形するRスクリプトが書けたところで、その全てを実行した後にマージするRスクリプトを書きました。
library(dplyr) #dplyrパッケージ呼び出し
library(stringr) #stringrパッケージ呼び出し
source("Paper_Ja.R") #各スクリプト実行
source("Paper_Ja_Google.R")
source("Online_Ja.R")
source("Paper_En.R")
source("Paper_En_Google.R")
source("Online_En.R")
Data <- rbind(Paper_Ja, Paper_Ja_Google, Online_Ja, Paper_En,Paper_En_Google, Online_En) #統合
sapply(Data,class) #型の確認
write.csv(Data,"Merged_Data.csv") #CSV書き出し
rbind()は単純に、列数等が揃っているdatabaseを縦に繋げる関数です。一気に指定できますが、指定した順番通りに繋がっていきます(今回は日本語が優先、紙が準優先という感じで並べました)。
これであとはそれぞれのデータセットに更新が入る度に、このRスクリプトを実行するだけでデータが分析可能な感じに整形された上で全部統合されます。めでたし。
あとはどんな感じで分析するかなんですけどね。がんばるぞ。ggplot2でグラフを描くとなんかかっこいいらしいので勉強するつもりです。ゼミ発表が近いが間に合うのか…。