Rでデータを綺麗にした(修論編)
この記事は修論で実施したアンケートの回答データを分析するため、Rでいい感じに整形したときの備忘録です。
見せたい気持ちは山々ですが、アンケートのデータをそのまま載せるとヤバいし、かといってサンプルデータをこしらえる気力も無いので抽象的な書き方が多いです。それでも卒論とかでRをやろうとしてる人とかの役に立ったら幸いです(高度なことはやらないですたぶん)。
はじめに
筆者のレベル
数学超苦手(だけど3DCGのために行列をちょっと自学しはじめた)。プログラミングの素養はそんな無いけどコンソールとかに抵抗はない(むしろRコマンダーとかGUI使う方がなんかめんどい)。
卒論でもRはちょっと触った。ディレクトリの概念とか簡単な関数くらいはわかる。
という感じで分かる通り、かなり初心者です。
やりたいこと
色々事情があって「日本語 or 英語」×「紙回収を手打ち or Googleフォーム回収」=4種類(厳密には6種類…ひえ…)の回答データセットが混在しており、それらを分析前に1つのデータベースにまとめる。それぞれ微妙に言語やフォーマット等が違うのでそれも統一する。
なぜRを使うに至ったか
上記のことはゴリ押しでやればExcelでもできます。ですが
筆者はExcel(というかOffi●e系ソフト)が嫌い。元データはできるだけ触りたくなかった。
中間報告(ゼミ等)が必要だったりするのもあり、アンケートが少しずつ集まるその都度に分析を進める形になる見込みだった。毎回手作業でしていてはめんどくさいし、何よりミスが怖いので、ある程度自動化したかった。
結局分析自体もRでやるので、練習・肩慣らしも兼ねて。
やっていく
ディレクトリを指定
いつも使ってるディレクトリが結構奥深くにあって、「ファイル→ディレクトリの変更」でいちいち指定するのがかなりめんどくさいので、関数で指定してやります。
setwd("ディレクトリ名")
で指定できます。
一度ディレクトリを開いてから、
getwd()
を実行するとディレクトリ名を吐き出してくれるので、コピペすると良いです。次から楽しましょう。
パッケージ呼び出し
今回はdplyrパッケージとstringrパッケージを使うので、
library(dplyr) library(stringr)
で呼び出しておきます。色々とデータ整形に便利なパッケージらしいです。
データを読み込む
data <- read.csv("ファイル名")
で読み込みます。
読み込むと、Rくんはこれを単なるmatrix(行列)ではなくいきなりdatabaseとして扱ってくれます。何も指定しないと、1行目が列名として使用されます。
1列目を除去する
紙回収で私が手入力したcsvファイルには、ミス等のチェック用に1列目に各解答用紙と紐づけたid番号を入力してあります。Googleフォーム(スプレッドシート)からDLできるファイルの1列目には「Timestamp(フォームが提出された日時時刻)」が格納されています。
今回は、どちらも使用しない(分析用のidは必要に応じて、マージしてから改めて付与する)ので1列目をまとめて除去します。
data <- data[,-1]
[ , ]の左側は行列の行の方で、右側は列の方を指します。-(マイナス)をつけると「その行(列)を除去する」という操作になります。空欄なら何も起こりません。
列名を付け直す
4つのデータセットは現在それぞれ列名が結構バラバラなので、命名しなおして統一します。
colnames(data) <- ("A", "B", "C"...)
みたいな感じで全て同じものを入力しましょう(上書きされます)。
※ちなみに、Rは日本語に対応しているはずなのでこれは私の趣味ですが、基本的にRコンソール上の文字列には日本語(2バイト文字)は使いません。2バイト文字を使うと、入力や選択の時になんか2バイトの分ズレて凄く使いにくくなるからです2。行の後ろの方であればあまり影響がないので、コメントアウトとかには容赦なく日本語使います。英語ワカラン。
列(属性)を足す
4つのデータセットにはそれぞれ「日本語 or 英語」×「紙回収を手打ち or Googleフォーム回収」という属性があるので、マージ前にその情報を付与します(後で言語・形式という実験方法の差による影響がないかを検証するためです)。
dplyrパッケージの中に、mutate()関数というピッタリなものがあります。databaseの列の末尾に新たな列を追加し、任意の値で埋めてくれます。
「日本語」版のアンケートを「紙回収して手打ち」したデータセットの場合、
data <- mutate(data, Language = "Japanese") data <- mutate(data, Format = "Paper")
を実行すると、LanguageとFormatという列名の列が末尾に追加され、Languageの列にJapaneseが、Formatの列にPaperがすべて入力されます。
(Googleフォーム産)順位を数値化
この辺からちょっと苦しくなってきます。
今回とったアンケートでは、8列目までが順位データとなっているのですが、Googleフォームでやる3とこんな感じになってしまいます。
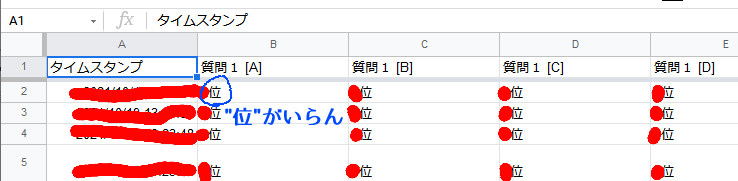
最終的に整数データとして扱いたいため、"位"とか、英語版なら"th"とかがとても邪魔です。
ここでもmutate()が役に立ちます。先ほどの用法では新たな列を作成するために用いましたが、引数に元ある列を指定することで処理後の値で中身を上書きできます。mutate()の最後の=の後には別の関数を実行することができます。
”位”の除去(というよりは、数値の抽出)にはsubstr()かstr_sub()を使います。たぶんどっちでもあんまりかわらないです(str_sub()を使うにはstringrパッケージが必要です)。
data <- mutate(data, A = str_sub(A,1,1))
という感じで、A列のそれぞれの中身の文字列の、1文字目~1文字目(つまり1文字目のみ)を抽出できます4。
これを8回やるわけですが、めんどい! 何か良い手はないのか!とインターネットを探してみると、mutate_at()やらacross()やら、mutate()を複数列に渡って実行する用の関数バリエーションがあるらしい。これや!と思ったのですが問題発生。
なんかmutate_at()の中身の関数は、引数を色々使うやつだとRぢからが無いと使えないらしい?! 僕R初心者です。
参考: https://knknkn.hatenablog.com/entry/2020/06/23/113455
とにかく普通に使おうとして動かなかったので、いうても8回しかやらないこともあってごり押しでやることにしました。
data <- mutate(data, A = str_sub(A,1,1))%>% #"位"を除去 mutate(B = str_sub(B,1,1))%>% mutate(C = str_sub(C,1,1))%>% mutate(D = str_sub(D,1,1))%>% mutate(E = str_sub(E,1,1))%>% mutate(F = str_sub(F,1,1))%>% mutate(G = str_sub(G,1,1))%>% mutate(H = str_sub(H,1,1))
はい全部書いた。
%>%はdplyrパッケージを入れると付いてくる、パイプ演算子と呼ばれる、処理を連鎖してくれるやつ。data <- mutate(data,あたりまでの記述を省略できるので、こんだけ泥臭く書いても若干ですがスッキリしますね。
こいつらは元は文字列だったので、整数型(integer)として定義しなおしてあげます。それに使う関数as.integer()は、なんと!引数が要らない関数なので!今度こそmutate_at()が使えます。やった~~~!!
data <- mutate_at(data, vars(A:H), list(as.integer)) #型変換
この一行で8列全部型変換してくれます。超楽ですね。(list()は最初はfuns()にしてたけどR君に今は非推奨ダヨ!となんか怒られたのでよくわからんまま変えました)
属性データを英語に統一
9列目からは性別だとか年齢だとかの回答者属性の列となっています。しかし自分で手打ちしたやつは作業簡便化の為に数字(コード)だし、Googleフォーム産のやつは前述の仕様のせいで日本語だったり英語だったりで、全部バラッバラでこのままだと集計すらできないので、統一します。
やること自体はさっきと似てます。mutate()の中でstr_replace()を実行して置換しまくります。
data <- mutate(data, Gender = str_replace(Gender,"男性","male"))%>% #Gender表記統一 mutate(Gender = str_replace(Gender,"女性","female"))
上記は"男性"を"male"に、"女性"を"female"に置換する例です。これを属性と水準の分だけ、全部やります。やりました。コピペ作業ではあるけど、大変。
CSV形式でエクスポート
整形した後は、
write.csv(data,"ファイル名")
でcsvとして吐き出せます(オリジナルとは別名にしときましょう。フォルダを分けたりしてもいい)。Excelで開いて確認してみるとちゃんとなってると思います。
上記までをRスクリプトとして保存、実行
ここまでをまとめると、「日本語」版のアンケートを「オンライン回収」したデータセットの例だと
#オンライン日本語版アンケート
data <- read.csv("Online_Ja.csv")
data <- data[,-1] #1列目削除
colnames(data) <- ("A", "B", "C"...)
data <- mutate(data, Language = "Japanese")
data <- mutate(data, Format = "Online")
#順位を数値化するやつ(省略)
#属性データを英語に置換するやつ(省略)
Online_Ja <- data #後の為に格納
write.csv(data,"Formated_Online_Ja.csv") #とりあえず書きだしもしとく
みたいな感じですね。
これを「ファイル→新しいスクリプト」からRエディタを開いて、そこに打ち込んでそれぞれのデータセット別に名前(上の例だと"Online_Ja.R")をつけて保存しておきます。
保存したRスクリプトは、source()関数を使って
source("スクリプト名.R")
とかで実行できます。RStudio使ってるとRunとかもできて便利ですね。
データセットをまとめる
形式が揃うように整形するRスクリプトが書けたところで、その全てを実行した後にマージするRスクリプトを書きました。
library(dplyr) #dplyrパッケージ呼び出し
library(stringr) #stringrパッケージ呼び出し
source("Paper_Ja.R") #各スクリプト実行
source("Paper_Ja_Google.R")
source("Online_Ja.R")
source("Paper_En.R")
source("Paper_En_Google.R")
source("Online_En.R")
Data <- rbind(Paper_Ja, Paper_Ja_Google, Online_Ja, Paper_En,Paper_En_Google, Online_En) #統合
sapply(Data,class) #型の確認
write.csv(Data,"Merged_Data.csv") #CSV書き出し
rbind()は単純に、列数等が揃っているdatabaseを縦に繋げる関数です。一気に指定できますが、指定した順番通りに繋がっていきます(今回は日本語が優先、紙が準優先という感じで並べました)。
これであとはそれぞれのデータセットに更新が入る度に、このRスクリプトを実行するだけでデータが分析可能な感じに整形された上で全部統合されます。めでたし。
あとはどんな感じで分析するかなんですけどね。がんばるぞ。ggplot2でグラフを描くとなんかかっこいいらしいので勉強するつもりです。ゼミ発表が近いが間に合うのか…。